git stores history as a graph
This post is part of a series on Git Fundamentals:
- git stores history as a graph
- [How To] Set up unique SSH keys per client
Before we look at any git commands we are going to start with some mental models to help orient you to as to how git stores a history of your changes.
The first principle to learn is:
Git stores history as a Directed Acyclic Graph (DAG).
We start here because most git commands operate on this graph in one way or another.
To make sense of the term “Directed Acyclic Graph” and how it helps us understand git we shall look at each of those words one at a time:
If you are interested in a more formal definition you can visit the Directed acyclic graph page on Wikipedia.
If you already know graph theory feel free to skip ahead to the Directed part.
Graph
In mathematics a graph is a set of vertices (think nodes or objects) and edges (lines which connect those nodes). This is a fancy way to decribe a group of objects which are connected by lines.
If you have worked with git for any length of time you have certainly seen a graph view of your commits.
Text graphs like this are common in the official git documentation:
---1----2----4----7
\ \
3----5----6----8---
Here the numbers represent the commits and the lines represent the way those commits are connected.
Take the following screenshot, for example, of the gitk GUI showing 4 commits in a sample repo:
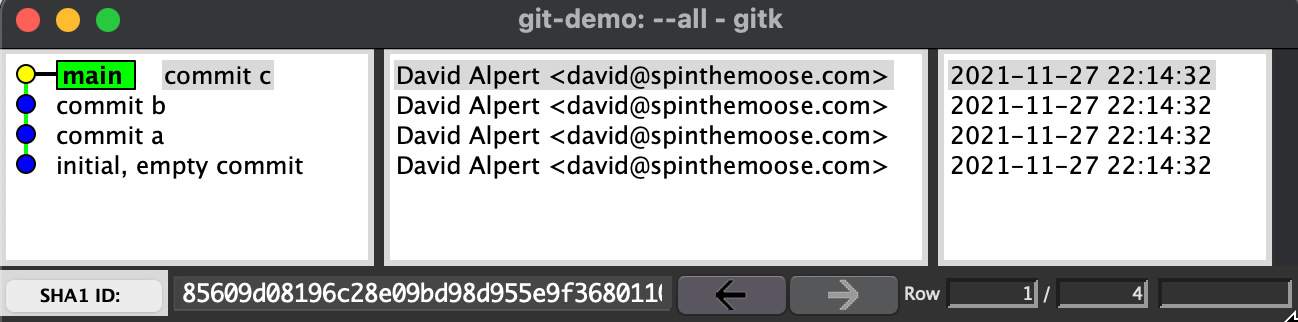
Each circle here represents a commit. The lines between commits represent the relationship between commits and their ancestors.
Here is another view of the same history:

You can get a similar view from the command line in a terminal:
git log
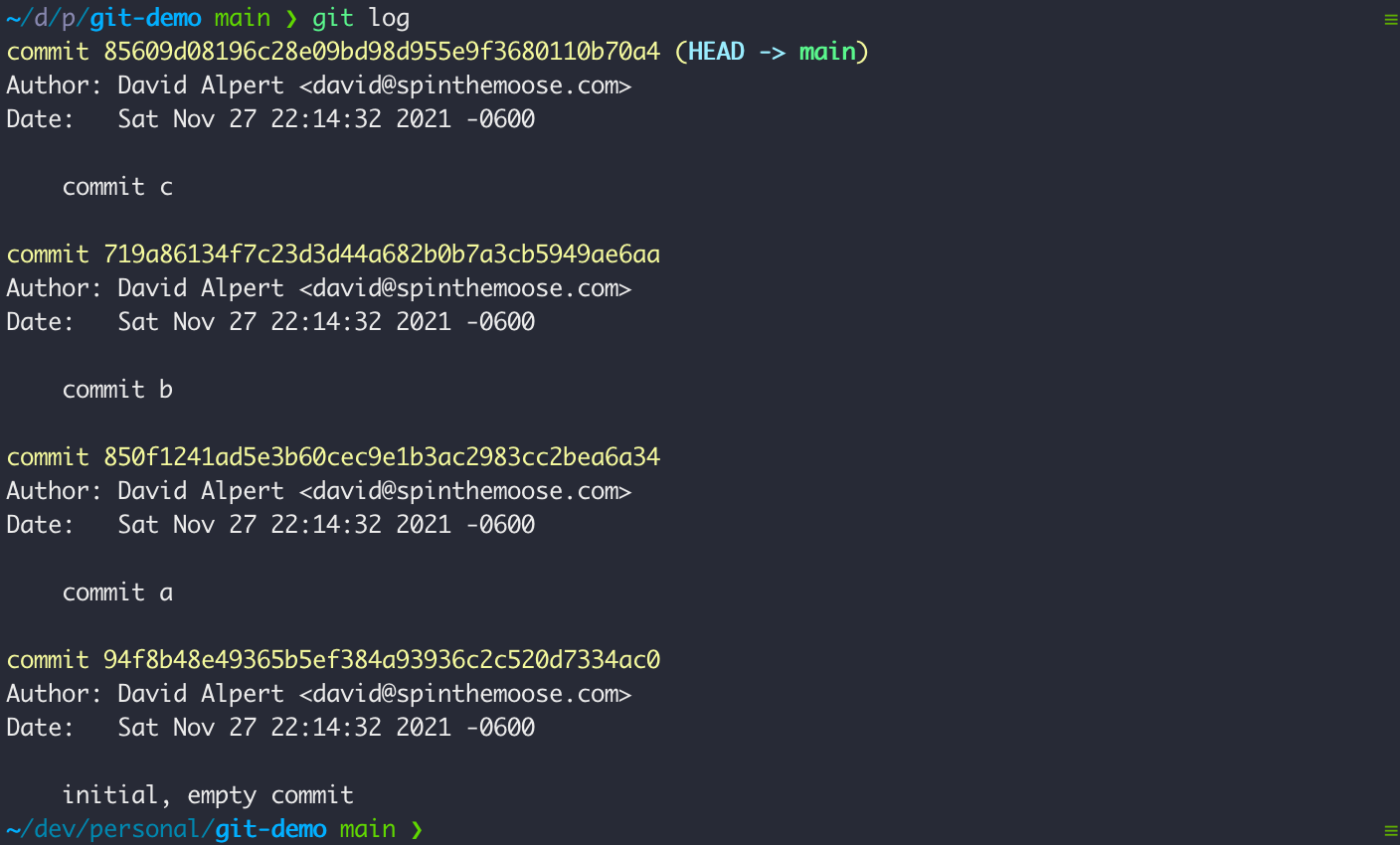
By default the git log command shows only the vertices but you can add a --graph flag to show the log as a textual graph:
git log --graph --pretty=tformat:'%Cred%h%Creset -%C(yellow)%d%Creset %s %-n%Cgreen(%ci)%Creset [%C(yellow)%an%Creset]%-n' --date=relative
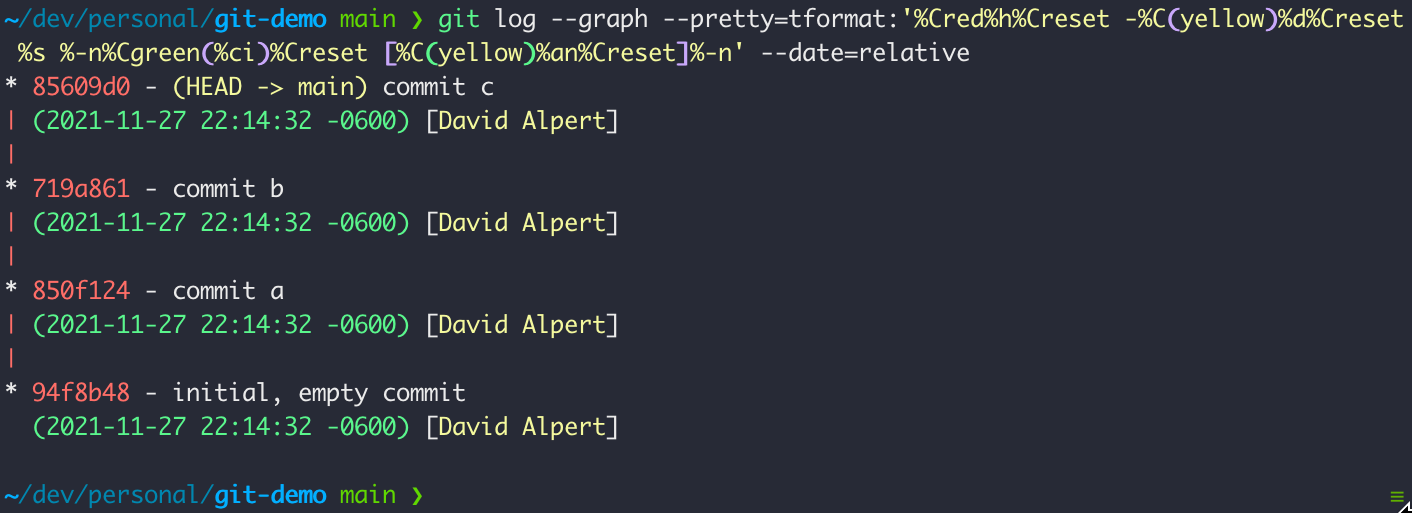
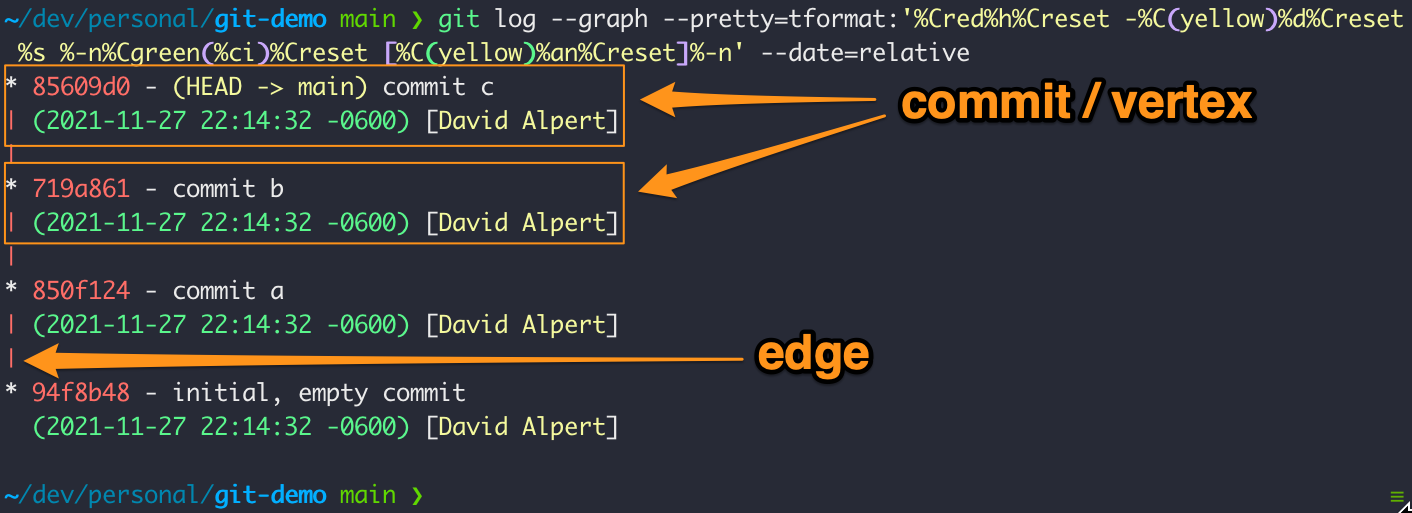
Here the commits are indicated by * and annotated with the SHA address, commit message, commit date, and author with edges drawn as pipes:
Directed
In mathematics a directed graph is a graph where the edges have a direction. This means that the lines on the graph become arrows.
<--1 <--2 <--4 <--7
^ ^
\ \
3 <--5 <--6 <--8 <-
In git terminology we talk about each commit having a reference or a pointer to its parent(s).
While it is common to think about arrows between commits pointing from parents to children to indicate the flow of time, it is more accurate in git terminology to speak of commits pointing to their parents.
In fact this baked into the data structure that git uses to store a commit:
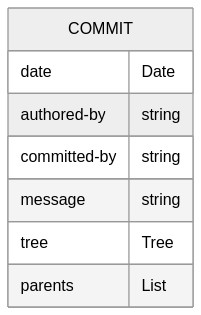
This may not be 100% accurate but it is close enough for our purposes.
Each git commit includes a list of one or more references to its parents:
- most commits have a single parent
- merge commits have one parent for each branch which was merged together
- the first commit in a repo is a special edge case having no parents
This provides an explicit “direction” to our graph of commits:
Is directed like this:

Acyclic
A graph is said to be “cyclic” when you can start at one node in the graph and traverse its directed edges in such a way as to wind up back where you started. Think of following the arrows to walk in a circle.
An “acyclic” graph, on the other hand, is a graph that has no cycles.
Acyclic graphs (graphs without cycles) have a number of mathematical properties which makes them more simpler and efficient to process in code.
For example, you can start processing any node of the tree and deterministically walk its parents without fear of entering a loop.
This is how git log determines which commits to show; by default it starts at the most recent commit and walks backwards showing you all the commits reachable from there.
We will revisit this concept when we talk about branches.
A note about SHAs
Work with git for any length of time and you will run into the term SHA.
SHA stands for Simple Hashing Algorithm. This algorithm is used to hash the contents of a commit and uniquely identify that commit in git’s history. A commit’s SHA can be though of as it’s unique identifier or unique address.
Remember when we looked at the data structure used to store a commit?
The SHA of a commit is generated by taking all of that information together.
It is important to recognize therefore that the SHA of a commit includes the date, author, message, and parents of that commit.
This is why certain git commands (e.g. amend, cherry-pick, rebase) appear to change the SHA of a commit.
If you move a change from one branch to another, the new commit will have different parents and therefore a different identifier.
This post is part of a series on Git Fundamentals:
- git stores history as a graph
- [How To] Set up unique SSH keys per client